Introduction¶
This notebook is a collection of examples that illustrate how to use PySpark with MLlib. This whole collection of examples is intended to be a gentle introduction to those interested in the topic, want to have additional examples, or simply are curious about how to start with this library.
The following skills are expected to follow these examples:
- Python
- Understanding Spark structures (Dataframes, RDD)
- Basic ML notions. This is not intended to be a ML course although, you can find some theoretical explanations.
The examples are designed to work with a simple local environment using the MLlib Dataframe. The MLlib RDD-based API is now in maintenance (see here). This is why you will see that the main import statement comes from pyspark.ml not pyspark.mllib.
You will need a spark environment to be available in your local path. Refer here to the official guide for more details.
You will need java to be available on your local path. Check it out running java --version. If nothing is displayed, check out how to install Java on your machine (here). Next, you can easily set up a local environment and install the dependencies used in this notebook.
virtualenv env
source env/bin/activate
pip install urllib3 numpy matplotlib pyspark
Wait until the dependencies are already satisfied. If you are not reading these lines from a Jupyter Notebook :) install and run it.
pip install jupyter
jupyter-notebook
Data types¶
Spark Dataframes support a collection of rows containing elements with different data types. In the context of ML algorithms, data types such as boolean, string or even integer are not the expected input for most ML algorithms. In this sense, MLlib supports data types such as vectors or matrices.
Dense Vectors¶
A dense vector is an array. PySpark uses numpy to run algebraical operations.
Sum: [10.0,11.0,12.0,13.0,14.0] Difference: [-10.0,-9.0,-8.0,-7.0,-6.0] Multiplication: [0.0,2.0,4.0,6.0,8.0] Division: [5.0,5.0,5.0,5.0,5.0] Non-zeros: (array([1, 2, 3, 4]),) Squared distance: 330.0
Sparse Vectors¶
Sparse vectors are designed to represent those vectors where a large number of elements is expected to be zero. These vectors are defined by specifying which positions of the array are different from zero and the assigned values. In
SparseVector (5 ,[0 ,2 ,4] ,[1 ,3 ,5])
we have five elements with entries 0, 2, and 4 take values 1, 3, and 5.
Sparse vector: [1. 0. 3. 0. 5.] Indices: [0 2 4] Non zeros: 3
Input/Output¶
We can expect datasets to be available from different storage sources:
- Hard disks
- HDFS
- Databases
- Others
The SparkSession object facilitates the load of data from these sources under different formats (CSV, JSON, text, parquet, databases, etc.). We will show examples for CSV, libSVM, and images.
CSV¶
Let's assume the following dataset in a CSV format:
csv
label,f1,f2,f3,f4
0,0,"one",2.0,true
1,4,"five",6.0,falseWe instantiate a SparkSession object and load the dataset indicating that we have a header and the separation character.
+-----+---+----+---+-----+ |label| f1| f2| f3| f4| +-----+---+----+---+-----+ | 0| 0| one|2.0| true| | 1| 4|five|6.0|false| +-----+---+----+---+-----+
libSVM¶
LibSVM is a popular format to represent numeric sparse data.
The following dataset:
0 128:51 129:159
1 130:253 131:159 132:50
1 155:48 156:238Where the first row 0 128:51 129:159 indicates an observation with label 0 and feature $128^{th}$ and $129^{th}$ equal to $51$ and $159$ respectively. We can load this dataset using the SparkSession object as we did for the CSV format.
+-----+--------------------+ |label| features| +-----+--------------------+ | 0.0|(157,[127,128],[5...| | 1.0|(157,[129,130,131...| | 1.0|(157,[154,155],[4...| +-----+--------------------+
Images¶
LMlib can load images in variety of formats (jpeg, png, etc.). It also supports compressed formats. The resulting DataFrame has a column image containing information of the schema.
More details in the docs

+---------------------+-----+------+---------+----+ |origin |width|height|nChannels|mode| +---------------------+-----+------+---------+----+ |file:///tmp/kitty.png|640 |960 |3 |16 | +---------------------+-----+------+---------+----+
Features¶
One of the main tasks for any data engineer is data preparation. For two reasons:
- Raw data is not ready to be consumed by algorithms
- Preprocessing data is required to improve algorithms performance
Incoming data has to be processed in different steps until we reach a successful representation to be consumed by algorithms. MLlib offers a collection of feature-related operations. We can distinguish:
- Extraction: extract features from raw data
- Transformation: modifying/converting features
- Selection: select features based on a certain criteria
- Locality Sensitive Hashing (LSH): algorithms combining feature transformation with other algorithms
In general feature processing in MLlib follows these steps:
- Instantiate the operator indicating the name of the input and output columns and additional params.
- Fit the model invoking the
.fit(...)method to train a model. Some operators may not require this step if they are not associated with a model. - Transform the input data using the model
No need to mention that these steps, the input params, and the input format vary from operator to operator.
The following sections present succint examples of different operators.
Normal standardization¶
Scale a feature to obtain a normal distribution with mean 0 and unit-variance.
$x'_i = \dfrac{x_i-\mu}{\sigma}$
Where
- $x_i$ is the feature value
- $\mu$ is the mean of the distribution and $\sigma$ is the standard deviation
- $x'_i$ becomes the standardized feature
+---+--------------+ | id| features| +---+--------------+ | 0|[1.0,0.1,-1.0]| | 1| [2.0,1.1,1.0]| | 2|[3.0,10.1,3.0]| +---+--------------+
Mean is: [2.0,3.7666666666666666,1.0] with sd: [1.0,5.507570547286102,2.0] +---+--------------+--------------------+ | id| features| standardized| +---+--------------+--------------------+ | 0|[1.0,0.1,-1.0]|[-1.0,-0.66575028...| | 1| [2.0,1.1,1.0]|[0.0,-0.484182026...| | 2|[3.0,10.1,3.0]|[1.0,1.1499323120...| +---+--------------+--------------------+
We can check if the transformed data has the desired distribution using a Summarizer (docs here). For every feature we have mean set to 0 and standard deviation equal to 1.
+---------------------------------------------+
|aggregate_metrics(standardized, 1.0) |
+---------------------------------------------+
|{[0.0,0.0,0.0], [1.0,0.9999999999999999,1.0]}|
+---------------------------------------------+
Elementwise product¶
This transformer multiplies each input vector by a provided vector, using element-wise multiplication. This operation scales each column by a given scalar (Hadamard product). For example:
$$ \begin{bmatrix} 2 & 3 & 1 \\ 0 & 8 & -2 \end{bmatrix} \circ \begin{bmatrix} 3 & 1 & 4 \end{bmatrix} = \begin{bmatrix} 2 \times 3 & 3 \times 1 & 1 \times 4 \\ 0 \times 3 & 8 \times 1 & -2 \times 4 \end{bmatrix} = \begin{bmatrix} 6 & 3 & 4 \\ 0 & 8 & -8 \end{bmatrix} $$b = [3.0,1.0,4.0]
+--------------+ | features| +--------------+ | [2.0,3.0,1.0]| |[0.0,8.0,-2.0]| +--------------+ +--------------+--------------+ | features| product| +--------------+--------------+ | [2.0,3.0,1.0]| [6.0,3.0,4.0]| |[0.0,8.0,-2.0]|[0.0,8.0,-8.0]| +--------------+--------------+
Principal Component Analysis¶
When dealing with many features we can come across the curse of dimensionality.
- More than three variables are difficult to plot
- Performance issues for a large number of features
- Features that only add "noise" to the problem
- Algorithms may find difficult to converge to a solution
Principal Component Analysis (PCA) is a dimensionality reduction technique that aims to find the components that maximize the variance. These are the steps to follow:
- Standardize the data
- Compute eigenvectors and eigenvalues of the covariance matrix
- Sort eigenvalues and pick the $d$ larges values
- Construct matrix $\mathbf{W}$ using the $d$ corresponding eigenvectors
- Transform dataset $\mathbf{X}$ multiplying it by $\mathbf{W}$
The covariance matrix is a symmetric matrix with the covariance between variables. It looks like this
$$ \mathrm{cov}(X_i, X_j) = \mathrm{E}\begin{bmatrix} (X_i - \mu_i)(X_j - \mu_j) \end{bmatrix} = \mathrm{E}\begin{bmatrix}X_iX_j \end{bmatrix} - \mu_i\mu_j $$$$ \mathrm{cov}(\mathbf{X},\mathbf{Y})= \begin{bmatrix} \mathrm{cov}(X_1,Y_1) & \mathrm{cov}(X_1,Y_2) & \cdots & \mathrm{cov}(X_1,Y_n) \\ \\ \mathrm{cov}(X_2,Y_1) & \mathrm{cov}(X_2,Y_2) & \cdots & \mathrm{cov}(X_2,Y_n) \\ \\ \vdots & \vdots & \ddots & \vdots \\ \\ \mathrm{cov}(X_n,Y_1) & \mathrm{cov}(X_n,Y_2) & \cdots & \mathrm{cov}(X_n,Y_n) \\ \\ \end{bmatrix} $$In MLlib there is a PCA transformer that implements all these steps. By applying the PCA we can obtain a reduced version of the original that maintains most of the relevant information brought by the features.
In the example below, we compute the PCA for a dataset of 5 features we wish to convert in a new 3 features dataset.
+--------------------+ | features| +--------------------+ |[1.0,0.0,3.0,0.0,...| |[2.0,0.0,3.0,4.0,...| |[4.0,0.0,0.0,6.0,...| +--------------------+
The variance for every new feature [0.84375,0.15625000000000008,4.509331675237028e-17]
+---------------------+---------------------------------------------------------+ |features |pcaFeatures | +---------------------+---------------------------------------------------------+ |[1.0,0.0,3.0,0.0,7.0]|[0.8164965809277265,3.65148371670111,-2.5144734900027204]| |[2.0,0.0,3.0,4.0,5.0]|[-2.857738033247042,0.9128709291752779,-2.51447349000272]| |[4.0,0.0,0.0,6.0,7.0]|[-6.53197264742181,3.6514837167011094,-2.514473490002719]| +---------------------+---------------------------------------------------------+
Observe that the transformed dataset does no longer correspond to any real observation. Any model predictions generated using this transformed data for training, has to be reconstructed. Otherwise, the output will no make any sense.
StringIndexer¶
This is a label indexer that assigns a label to every string in a column. If the value is numeric, first it is casted to string and then indexed.
+-------+ |feature| +-------+ | blue| | red| | red| | white| | yellow| | red| +-------+ Found labels: ['red', 'blue', 'white', 'yellow'] +-------+-----+ |feature|index| +-------+-----+ | blue| 1.0| | red| 0.0| | red| 0.0| | white| 2.0| | yellow| 3.0| | red| 0.0| +-------+-----+
One hot encoder¶
This encoder maps a column of indices into a single binary vector. If we have 4 labels, for index 3 we will have $[0,0,0,1,0]$. The output is a SparseVector.
Observe that the param dropLast is True by default ignoring the label with index $n-1$.
+-------+ |feature| +-------+ | blue| | red| | red| | white| | yellow| | red| +-------+ +-------+-------+ |feature|indexed| +-------+-------+ | blue| 1.0| | red| 0.0| | red| 0.0| | white| 2.0| | yellow| 3.0| | red| 0.0| +-------+-------+ +-------+-------+-------------+ |feature|indexed| encoded| +-------+-------+-------------+ | blue| 1.0|(4,[1],[1.0])| | red| 0.0|(4,[0],[1.0])| | red| 0.0|(4,[0],[1.0])| | white| 2.0|(4,[2],[1.0])| | yellow| 3.0|(4,[3],[1.0])| | red| 0.0|(4,[0],[1.0])| +-------+-------+-------------+
Tokenization¶
Tokenization is the process of splitting a document into a vector of differentiated tokens. The sentence "The quick brown fox jumps over the lazy dog" will be split into tokens like in ["The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"]. Different approaches may split the document using white spaces, commas, regular expressions, or any other character.
In MLlib there is a Tokenizer transformer for this purpose.
+---+---------------------------------------+---------------------------------------------+ |id |sentence |words | +---+---------------------------------------+---------------------------------------------+ |0 |Hi I heard about Spark |[hi, i, heard, about, spark] | |1 |I wish Java could use case classes |[i, wish, java, could, use, case, classes] | |2 |Logistic, regression, models, are, neat|[logistic,, regression,, models,, are,, neat]| +---+---------------------------------------+---------------------------------------------+
Stop words¶
Natural language is redundant and not every term provides the same amount of information. By stop words we refer to the most common words in a given language. These words are so common that result into non-relevant chunks of information. These words are removed previously to any analysis. There is no a single list of stop words and this changes with every language.
MLlib implements the StopWordsRemover that filters out stop words using a dictionary.
+---+------------------------------+ |id |raw | +---+------------------------------+ |0 |[I, saw, the, red, balloon ] | |1 |[Mary, had, a, little , lamb]| +---+------------------------------+ +---+------------------------------+----------------------+ |id |raw |filtered | +---+------------------------------+----------------------+ |0 |[I, saw, the, red, balloon ] |[saw, red, balloon ] | |1 |[Mary, had, a, little , lamb]|[Mary, little , lamb]| +---+------------------------------+----------------------+
Count Vectorizer¶
This estimator counts the number of occurrences of items in a vocabulary represented in a sparse vector. This is particularly useful to represent a document in terms of the frequency of its elements and it is normally used in probabilistic models.
+---+-------------------+ | id| raw| +---+-------------------+ | 0|[yellow, red, blue]| | 1| [red]| | 2|[blue, white, blue]| +---+-------------------+ The vocabulary: ['blue', 'red', 'white', 'yellow'] +---+-------------------+-------------------------+ |id |raw |frequencies | +---+-------------------+-------------------------+ |0 |[yellow, red, blue]|(4,[0,1,3],[1.0,1.0,1.0])| |1 |[red] |(4,[1],[1.0]) | |2 |[blue, white, blue]|(4,[0,2],[2.0,1.0]) | +---+-------------------+-------------------------+
N-grams¶
N-grams are a common input for many algorithms to understand the probability of $n$ words to occur together. The NGram transformer outputs a collection of these N-grams.
+-----+-----------------------------------+------------------------------------------+ |label|sentence |words | +-----+-----------------------------------+------------------------------------------+ |0 |Hi I heard about Spark |[hi, i, heard, about, spark] | |0 |I wish Java could use case classes |[i, wish, java, could, use, case, classes]| |0 |Logistic regression models are neat|[logistic, regression, models, are, neat] | +-----+-----------------------------------+------------------------------------------+ +-----+-----------------------------------+------------------------------------------+------------------------------------------------------------------+ |label|sentence |words |ngrams | +-----+-----------------------------------+------------------------------------------+------------------------------------------------------------------+ |0 |Hi I heard about Spark |[hi, i, heard, about, spark] |[hi i, i heard, heard about, about spark] | |0 |I wish Java could use case classes |[i, wish, java, could, use, case, classes]|[i wish, wish java, java could, could use, use case, case classes]| |0 |Logistic regression models are neat|[logistic, regression, models, are, neat] |[logistic regression, regression models, models are, are neat] | +-----+-----------------------------------+------------------------------------------+------------------------------------------------------------------+
TF-IDF¶
Computing the number of occurrences of a term in a document or a collection of documents we can weight its relevance (here.
- Term-frequency (tf): the ratio of occurrences of a term in a document among the total
- Inverse document frequency (idf): measure of how much information the term provides
Let's assume a corpus of documents $D$ with two documents $d_1$ and $d_2$. With the terms and their frequencies shown below:
Document $d_1$
| term | frequency |
|---|---|
| this | 1 |
| is | 1 |
| a | 2 |
| sample | 1 |
Document $d_2$
| term | frequency |
|---|---|
| this | 1 |
| is | 1 |
| another | 2 |
| sample | 3 |
If we want to understand the relevance of this in $d_1$ we can compute the tf and idf.
$$tf(this,d_1)=\dfrac{1}{5}$$The word this appears only one in $d_1$ from the total of $5$ terms (sum of all the frequencies).
$$idf(this, D) = log\dfrac{2}{2}=0$$With the idf we can get how relevant is this in the corpus $D$. It appears in both documents, therefore it does not bring too much information.
If we compute the same for another we can see the word is more relevant as it appears with a higher frequency but not in all the documents of the corpus $D$.
$$tf(another,d_2)=\dfrac{2}{7}$$$$idf(another, D) = log\dfrac{2}{1}=0.69$$We can combine both metrics using the tfidf to filter out common terms and highlight relevant terms:
$$ \mathbf{tfidf}(t,d,D)=\mathbf{tf}(t,d) \cdot\mathbf{idf}(t,D) $$With tfidf we can weight how relevant is a term inside a document considering how frequently it is found. For the previous example:
$$ \mathbf{tfidf}(\text{this},d1,D)=\dfrac{1}{5} \cdot 0 $$$$ \mathbf{tfidf}(\text{this},d1,D)=\dfrac{1}{5} \cdot 0 $$In a practical scenario we will use vectorized versions. For a vocabulary {a,b,c} and three documents:
| Input | TF-vector |
|---|---|
| {a,b,c} | {1,1,1} |
| {a,b,c,c,a} | {2,2,1} |
| {a,a,a,c,a} | {4,0,1} |
Usually the vocabulary is trimmed by discarded terms with a small idf to avoid non-relevant terms. This can be done using the params mindf and mintf from the CountVectorizer transformer. Take a look at the Bag of words section.
The following example computes the idf of a corpus using the IDF transformer.
+-----+----------------------------------+------------------------------------------+ |label|sentence |tokens | +-----+----------------------------------+------------------------------------------+ |0.0 |Java has been around for a while |[java, has, been, around, for, a, while] | |0.0 |I wish Java could use case classes|[i, wish, java, could, use, case, classes]| |0.0 |Objects belong to classes |[objects, belong, to, classes] | +-----+----------------------------------+------------------------------------------+
This is our vocabulary ['classes', 'java'] +-----+--------------------+--------------------+-------------------+ |label| sentence| tokens| frequencies| +-----+--------------------+--------------------+-------------------+ | 0.0|Java has been aro...|[java, has, been,...| (2,[1],[1.0])| | 0.0|I wish Java could...|[i, wish, java, c...|(2,[0,1],[1.0,1.0])| | 0.0|Objects belong to...|[objects, belong,...| (2,[0],[1.0])| +-----+--------------------+--------------------+-------------------+
+-----+----------------------------------+------------------------------------------+-------------------+---------------------------------------------------+ |label|sentence |tokens |frequencies |idf | +-----+----------------------------------+------------------------------------------+-------------------+---------------------------------------------------+ |0.0 |Java has been around for a while |[java, has, been, around, for, a, while] |(2,[1],[1.0]) |(2,[1],[0.28768207245178085]) | |0.0 |I wish Java could use case classes|[i, wish, java, could, use, case, classes]|(2,[0,1],[1.0,1.0])|(2,[0,1],[0.28768207245178085,0.28768207245178085])| |0.0 |Objects belong to classes |[objects, belong, to, classes] |(2,[0],[1.0]) |(2,[0],[0.28768207245178085]) | +-----+----------------------------------+------------------------------------------+-------------------+---------------------------------------------------+
Word2Vec¶
The Word2Vec represents the words of a document in a vector. This makes possible to operate with documents as vectors which makes possible to easily computes distances and enables other algorithms specially in NLP. Take a look at the original Google code here
+-------------------------------------------+ |words | +-------------------------------------------+ |[Spark, is, quite, useful] | |[I, can, use, Spark, with, Python] | |[Spark, is, not, so, difficult, after, all]| +-------------------------------------------+ +-------------------------------------------+------------------------------------------------------------------+ |words |result | +-------------------------------------------+------------------------------------------------------------------+ |[Spark, is, quite, useful] |[0.08182145655155182,-0.07318692095577717,-0.0631803400174249] | |[I, can, use, Spark, with, Python] |[0.016474373017748196,-1.7273581276337305E-4,-0.04478610997709135]| |[Spark, is, not, so, difficult, after, all]|[0.019738022836723497,0.029656097292900085,-0.033315843919159045] | +-------------------------------------------+------------------------------------------------------------------+
Pipelines¶
Most models are computed as a concatenation of operations, each operation transforming the original dataset. For example, normalization -> component analysis -> regression. MLlib uses the concept of pipelines (similinar to the one used in SciKit) to unify the execution of a sequence of steps into a single object.
The pipeline is defined as a sequence of stages connecting transformers and estimators:
- Transformer: receives an input dataframe and returns a transformed version (standardizers)
- Estimator: receives an input dataframe and after fitting returns a transformer (linear regression, logistic regression, etc.)
Creating a pipeline is equivalent to set the sequence of stages to be executed.
from pyspark.ml.pipeline import Pipeline
pipeline = Pipeline(stages=[standardizer, pca, lr])
Then we fit the model and transform the dataset to get the corresponding results:
model = pipeline.fit(dataset)
model.transform(dataset).show()
+-----------------------------------+ |docs | +-----------------------------------+ |Spark is quite useful | |I can use Spark with Python | |Spark is not so difficult after all| +-----------------------------------+ +-----------------------------------+-------------------------------------------+----------------------+-------------------------+ |docs |tokens |filtered |frequencies | +-----------------------------------+-------------------------------------------+----------------------+-------------------------+ |Spark is quite useful |[spark, is, quite, useful] |[spark, quite, useful]|(6,[0,2,3],[1.0,1.0,1.0])| |I can use Spark with Python |[i, can, use, spark, with, python] |[use, spark, python] |(6,[0,1,5],[1.0,1.0,1.0])| |Spark is not so difficult after all|[spark, is, not, so, difficult, after, all]|[spark, difficult] |(6,[0,4],[1.0,1.0]) | +-----------------------------------+-------------------------------------------+----------------------+-------------------------+ --> Tokenizer_346e29794e54 [Param(parent='Tokenizer_346e29794e54', name='inputCol', doc='input column name.'), Param(parent='Tokenizer_346e29794e54', name='outputCol', doc='output column name.')] --> StopWordsRemover_cdda6836267e [Param(parent='StopWordsRemover_cdda6836267e', name='caseSensitive', doc='whether to do a case sensitive comparison over the stop words'), Param(parent='StopWordsRemover_cdda6836267e', name='inputCol', doc='input column name.'), Param(parent='StopWordsRemover_cdda6836267e', name='inputCols', doc='input column names.'), Param(parent='StopWordsRemover_cdda6836267e', name='locale', doc='locale of the input. ignored when case sensitive is true'), Param(parent='StopWordsRemover_cdda6836267e', name='outputCol', doc='output column name.'), Param(parent='StopWordsRemover_cdda6836267e', name='outputCols', doc='output column names.'), Param(parent='StopWordsRemover_cdda6836267e', name='stopWords', doc='The words to be filtered out')] --> CountVectorizer_983c07eb2c8f [Param(parent='CountVectorizer_983c07eb2c8f', name='binary', doc='Binary toggle to control the output vector values. If True, all nonzero counts (after minTF filter applied) are set to 1. This is useful for discrete probabilistic models that model binary events rather than integer counts. Default False'), Param(parent='CountVectorizer_983c07eb2c8f', name='inputCol', doc='input column name.'), Param(parent='CountVectorizer_983c07eb2c8f', name='maxDF', doc='Specifies the maximum number of different documents a term could appear in to be included in the vocabulary. A term that appears more than the threshold will be ignored. If this is an integer >= 1, this specifies the maximum number of documents the term could appear in; if this is a double in [0,1), then this specifies the maximum fraction of documents the term could appear in. Default (2^63) - 1'), Param(parent='CountVectorizer_983c07eb2c8f', name='minDF', doc='Specifies the minimum number of different documents a term must appear in to be included in the vocabulary. If this is an integer >= 1, this specifies the number of documents the term must appear in; if this is a double in [0,1), then this specifies the fraction of documents. Default 1.0'), Param(parent='CountVectorizer_983c07eb2c8f', name='minTF', doc="Filter to ignore rare words in a document. For each document, terms with frequency/count less than the given threshold are ignored. If this is an integer >= 1, then this specifies a count (of times the term must appear in the document); if this is a double in [0,1), then this specifies a fraction (out of the document's token count). Note that the parameter is only used in transform of CountVectorizerModel and does not affect fitting. Default 1.0"), Param(parent='CountVectorizer_983c07eb2c8f', name='outputCol', doc='output column name.'), Param(parent='CountVectorizer_983c07eb2c8f', name='vocabSize', doc='max size of the vocabulary. Default 1 << 18.')]
Linear Regression¶
The Spark MLlib offers a linear regression implementation with $L_1$, $L_2$ and ElasticNet regularization.
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(maxIter=10, regParam=0.3)
In a naive example where we have a set of observatios corresponding to the equation $y=2x+3$:
| y | x |
|---|---|
| 7 | 2 |
| 9 | 3 |
| 23 | 10 |
We will train a model based on these observations to predict the output for $x=5$. Obviously, this will be $y=13$ ($y=2\times 5 + 3$).
+-----+--------+ |label|features| +-----+--------+ | 7.0| [2.0]| | 9.0| [3.0]| | 23.0| [10.0]| +-----+--------+ Train our model...
Now that we have trained our model we can investigate how does it look internally.
These are the weights for our model: Coefficients: [1.9999999999999998] Intercept: 3.000000000000002
Unsurprisingly, we have a coefficient near 2 and the intercept value is 3. We were trying to model a linear function so it was a straight forward case.
We can check how was the training in terms of error, iterations, etc.
This is the training summary: Num iterations: 0 Residuals: +--------------------+ | residuals| +--------------------+ |-1.77635683940025...| |-1.77635683940025...| | 0.0| +--------------------+ RMSE: 0.000000
Now we are going to predict new outputs. We simply feed the model with dataframes using the same format we used to train it.
+-----+--------+----------+ |label|features|prediction| +-----+--------+----------+ | 13.0| [5.0]| 13.0| +-----+--------+----------+
Because our model is basically perfect, we have a prediction of 13 which is what we were expecting.
In a more complex scenario, we will need to know how good is our model doing. We can check the error using any of the available error evaluators. In this case, for a linear regression we can use the RegressionEvaluator. For our predictions this value will be 0 because we committed no mistakes.
0.0
Logistic Regression¶
The Spark MLLib offers a logicstic regression implementation for binominal and multinomial problems in the classification package (docs here for more details.)
The example below trains a binary classifier to identify whether a point is contained inside a circle or not.
| x | y | inside |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 2 | 0 |
| 2 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0.3 | 0.87 | 1 |
| 1 | -1.3 | 1 |
| 0.9 | -1.2 | 1 |
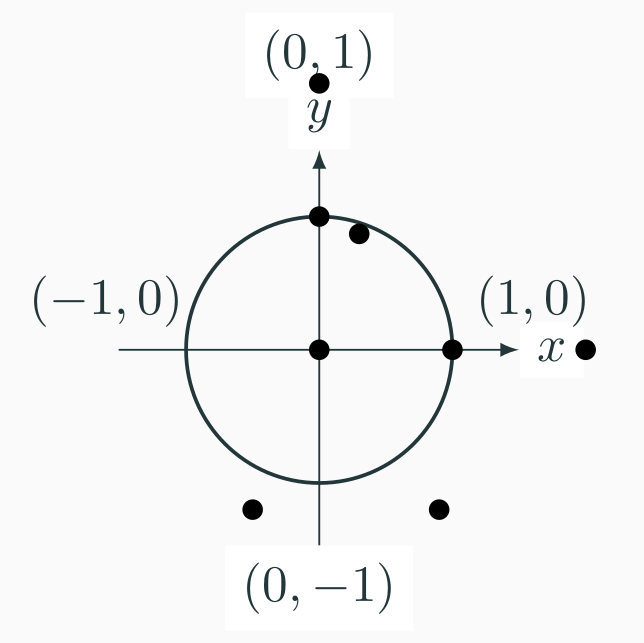
Similarly to what we did with the linear regression, we define our dataset based on the observations to fit our model.
+-----+----------+ |label| features| +-----+----------+ | 1.0| [0.0,0.0]| | 0.0| [0.0,2.0]| | 0.0| [2.0,0.0]| | 1.0| [1.0,0.0]| | 1.0| [0.0,1.0]| | 1.0|[0.3,0.87]| | 0.0|[1.0,-1.3]| | 1.0|[0.9,-1.2]| +-----+----------+
Coefficients: [-2.6073306122669933,-1.002969191804841] Intercept: 2.380173815124733
We can take a look at the errors during the training phase. In this case, we look at the ROC curve, the AUC, and the F-measure by threshold.
We can take a look at the ROC curve and the AUC
+------------------+---+ | FPR|TPR| +------------------+---+ | 0.0|0.0| | 0.0|0.2| | 0.0|0.4| | 0.0|0.6| |0.3333333333333333|0.6| |0.3333333333333333|0.8| |0.6666666666666666|0.8| |0.6666666666666666|1.0| | 1.0|1.0| | 1.0|1.0| +------------------+---+ AUC: 0.800000 +--------------------+-------------------+ | threshold| F-Measure| +--------------------+-------------------+ | 0.9153029099975847|0.33333333333333337| | 0.7985416752560925| 0.5714285714285715| | 0.7750656745222227| 0.7499999999999999| | 0.7458695786407464| 0.6666666666666665| | 0.6737931410385649| 0.8000000000000002| | 0.5924820101887259| 0.7272727272727272| | 0.44345374176351793| 0.8333333333333333| |0.055488744288528125| 0.7692307692307693| +--------------------+-------------------+
The ROC curve looks much nicer if we have a real curve.

We do not have too many points to draw so our ROC curve looks so steeped.
Kmeans Clustering¶
MLlib offers an implementation of KMeans with centroids initialization using [KMeans++] (https://en.wikipedia.org/wiki/K-means%2B%2B) (docs)
The following example runs KMeans with $k=2$
+----------+ | features| +----------+ | [0.0,0.0]| | [0.0,2.0]| | [2.0,0.0]| | [1.0,0.0]| | [0.0,1.0]| |[0.3,0.87]| |[1.0,-1.3]| |[0.9,-1.2]| +----------+
Once the model is fit, we can take a look at the predicted clusters and the generated centroids.
Centroids [array([0.45714286, 0.19571429]), array([2., 0.])]
+----------+----------+ | features|prediction| +----------+----------+ | [0.0,0.0]| 0| | [0.0,2.0]| 0| | [2.0,0.0]| 1| | [1.0,0.0]| 0| | [0.0,1.0]| 0| |[0.3,0.87]| 0| |[1.0,-1.3]| 0| |[0.9,-1.2]| 0| +----------+----------+
For a more visual analysis, we can plot the centroids and the reference circle. There is not too much data for a good clustering. However, the centroids are located inside and outside the circle which in a first attempt looks promising. Obviously the data distribution is a bit biased and forces one of the centroids to the bottom right. How the algorithm would evolve with a more uniformly distributed dataset remains as an additional exercise.
Observe that we need some workaround to get the correct numpy shape for our plot.

Topic Modelling¶
The Latent Dirichlet Allocation (LDA) (do not confuse with Linear Discriminant Analysis) is a method for topic modelling. This method can be used to extract the topics contained in a corpus. For example: extract the topics from a collection of users' opinions, main ideas discussed in wiki-leaks, etc.
LDA represents documents as a mixture that spit out words with certain probabilities. The final model is solved using bayesian inference.
$$ P(\boldsymbol{W}, \boldsymbol{Z}, \boldsymbol{\theta}, \boldsymbol{\varphi};\alpha,\beta) = \prod_{i=1}^K P(\varphi_i;\beta) \prod_{j=1}^M P(\theta_j;\alpha) \prod_{t=1}^N P(Z_{j,t}\mid\theta_j)P(W_{j,t}\mid\varphi_{Z_{j,t}}) $$where
- $\alpha$ is the parameter of the Dirichlet prior on the per-document topic distributions
- $\beta$ is the parameter of the Dirichlet prior on the per-topic word distribution
- $\theta_{m}$ is the topic distribution for document m
- $\varphi_{k}$ is the word distribution for topic k
- $z_{mn}$ is the topic for the n-th word in document m
- $w_{mn}$ is the specified word
In pseudocode the algorithm can be described as follows [Blei et al.]:
Assign randomly each word in every document a topic
for number of iterations do
for every word w in document d do
for each topic t ∈ K do
Compute the proportion of words in d assigned to t
Compute the proportion of assignments to t that come from w
Reassign a new topic using p(t|d) · p(w|t)
end for
end for
end for
After a certain number of iterations, LDA reaches a steady state with a mixture of topics per document. Every document belongs to the $K$ topics with a certain probability. A plausible example could be as follows:
| Document | Probability topic 1 | Probability topic 2 |
|---|---|---|
| I like apples | 1 | 0 |
| I eat apples | 0 | 1 |
| There is no white apples | 0.8 | 0.2 |
| I don't eat apples | 0.3 | 0.7 |
Spark MLlib offers and LDA implementation using:
- EMLDAOptimizer: batch approach
- OnlineLDAOptimizer: incremental learning solution
The fitted model offers a description of the $K$ topics and the transformer computes the probability of every document to belong to every topic as described above (ref).
+-----+----------------------------------+------------------------------------------+ |label|sentence |tokens | +-----+----------------------------------+------------------------------------------+ |0.0 |Java has been around for a while |[java, has, been, around, for, a, while] | |0.0 |I wish Java could use case classes|[i, wish, java, could, use, case, classes]| |0.0 |Objects belong to classes in Java |[objects, belong, to, classes, in, java] | +-----+----------------------------------+------------------------------------------+ This is our vocabulary ['java', 'classes'] +-----+--------------------+--------------------+-------------------+ |label| sentence| tokens| frequencies| +-----+--------------------+--------------------+-------------------+ | 0.0|Java has been aro...|[java, has, been,...| (2,[0],[1.0])| | 0.0|I wish Java could...|[i, wish, java, c...|(2,[0,1],[1.0,1.0])| | 0.0|Objects belong to...|[objects, belong,...|(2,[0,1],[1.0,1.0])| +-----+--------------------+--------------------+-------------------+
+-----+-----------+----------------------------------------+ |topic|termIndices|termWeights | +-----+-----------+----------------------------------------+ |0 |[0, 1] |[0.591822231531493, 0.40817776846850695]| |1 |[0, 1] |[0.6081744624264148, 0.3918255375735851]| +-----+-----------+----------------------------------------+
Evaluation¶
In order to understand the correctness of a model we need to compute its associated prediction error. First, we have to understand that during the training phase (fitting) our model should not use observations used during the evaluation phase. In this way, we check if our model can really make predictions on an observation never seen before and avoid potential overfitting. To do so, we have to differentiate between training and test datasets.
For the evaluation, MLlib offers a collection of evaluators. Depending on the prediction problem we are working on, we have to select the corresponding error evaluator which usually supports a variety of metrics.
Random split¶
A simple way to obtain is using the randomSplit method from the data frame objects. We simply indicate the ratio from the total of rows dedicated to the train and evaluation and we get both
+---+--------------------+ | id| doc| +---+--------------------+ | 0|I think I saw som...| | 1| PySpark is awesome| | 2|Python = data powers| | 3|You don't need sc...| | 4|Programming is an...| +---+--------------------+ Our training dataset +---+-----------------------+ |id |doc | +---+-----------------------+ |0 |I think I saw something| |2 |Python = data powers | |4 |Programming is an art | +---+-----------------------+ Our evaluation dataset +---+---------------------------------+ |id |doc | +---+---------------------------------+ |1 |PySpark is awesome | |3 |You don't need scala to use Spark| +---+---------------------------------+
Binary classification¶
The BinaryClassificationEvaluator expects a column with the labels and one with the predictions. The predictions can be represented in two ways:
- Type double. Where we represent binary values 0/1 or the probability of having label 1.
- Length 2 vector. Raw predictions, scores, or label probabilities.
Two different metrics can be selected with the metricName param: areaUnderPR or areaUnderROC. Check the docs for more details.
+-----+----------+ |label|prediction| +-----+----------+ | 1.0| 0.35| | 1.0| 0.9| | 1.0| 0.18| | 0.0| 1.0| +-----+----------+
Regression¶
Evaluator for regression models. The following metrics can be specified in the metricName param:
- rmse: root mean squared error (default)
- mse: mean squared error
- r2: $r^2$ metric
- mae: mean absolute error
- var: explained variance
+-----+----------+ |label|prediction| +-----+----------+ | 15.0| 11.0| | 5.32| 6.0| | 1.4| 3.8| | 5.0| 1.8| +-----+----------+
Cross-validation¶
Cross validation splits the dataset into $k$ folds and uses $k-1$ folds for training and one fold for evaluation. This operaiton is done $k$ times ensuring variability during the process.
Assuming $k=4$ we split a dataset $D$ into $\{D_0,D_1,D_2,D_3\}$ generating the training-evaluation pairs as shown below.
| Training | Evaluation |
|---|---|
| $$\{D_1,D_2,D_3\}$$ | $\{D_0\}$ |
| $$\{D_0,D_2,D_3\}$$ | $\{D_1\}$ |
| $$\{D_0,D_1,D_3\}$$ | $\{D_2\}$ |
| $$\{D_0,D_1,D_2\}$$ | $\{D_3\}$ |
The cross validation has several advantages:
- It is embarrasingly parallel
- The quality of a model is the average of its evaluation over the different evaluatio sets
- Userful approach to the hyperparameter problem
And some disadvantages:
- It can be very expensive with large datasets
- Transformations using information extracted from the whole dataset instead of the training folds may lead to biased results
In MLlib we simply have to configure a CrossValidator indicating the estimator, the evaluator, the params (if any) and the number of folds.
from pyspark.ml.tuning import CrossValidator
cv = CrossValidator(estimator=pipeline, evaluator=BinaryClassificationEvaluator(), estimatorParamMaps=paramGrid, numFolds=10)
The CrossValidator will use the evaluator to identify the best model. Then, it can be used as usual
cv_model = cv.fit(dataset)
cv_model.transform(testDataset)
The ParamGridBuilder permits to create a grid for the search of hyperparameters that can be later used in the cross validation.
from pyspark.ml.tuning import ParamGridBuilder
grid = ParamGridBuilder()
grid.addGrid(param=lm.elasticNetParam, values=[0.1,0.3])
grid.build()