What can Borges teach you about overfitting?
Table of Contents
Jorge Luis Borges (1899-1986) was a brilliant writter and one of the most influential authors of all times. His tales are a must-read for anyone interested in science/science-fiction. But what can Borges teach you about overfitting?
Funes the memorious#
Borges wrote Funes the memorious (originally “Funes el memorioso”) in 1954. This tale was born after the author suffered from insomnia. This tale tells the story of Ireneo Funes who suffers from hypermnesia. After a horseback riding accident, Funes discovers that he can remember absolutely everything: the shape of the clouds in every moment of the day, the position of the light in every corner of the house, what he did minute by minute two months ago, etc.

In this tale, Borges explores various topics regarding several aspects of our life that require the “art of forgetting”. By remembering absolutely everything Funes loses one of the most important features of the thinking process: generalization. Funes cannot understand how the term “dog” can group every dog if they are clearly different. He can easily differentiate the small black dog with shiny eyes from the small black dog with that red dot in the left eye, but he cannot understand what makes a dog to be a dog.
Overfitting or the lost of generalization#
Funes hypermnesia is more a misfortune than a gift. With no generalization is impossible to use abstract thinking. And without abstract thinking, Funes is closer to a machine rather than a human being. He goes into the opposite direction of what we expect to obtain with machine learning.
Overfitting is to machine learning what hypermnesia is to Funes. Overfitted models cannot distinguish between noisy observations and the underlying model. This is, they cannot generalize.
The figure below shows two binary classifiers (black and green lines). The overfitted classifier (green line) is very dependant on the training data and it is very likely to have a poor performance when new observations arrive.
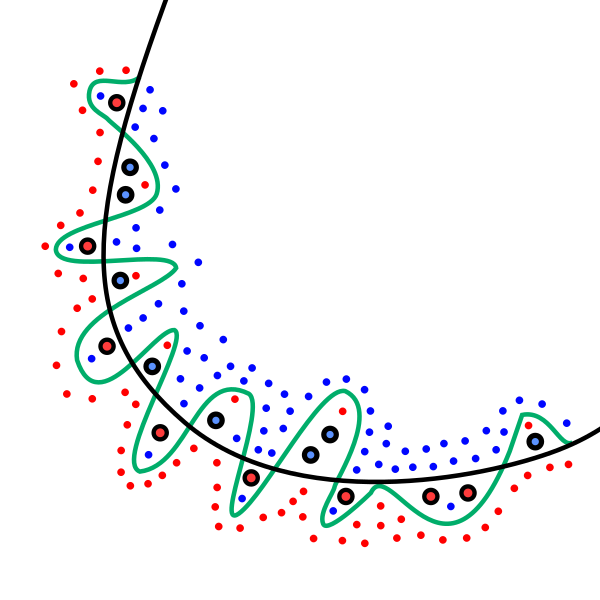
How do I know I have an overfitted model? When you observe a much better performance in your training set than in your testing set.
Then, how can I prevent overfitting?
- Consider large enough datasets. If your dataset is too small your model will simply learn by heart ignoring any general rules.
- Cross validation always in mind.
- Regularization always helps.
- Ensembles of models can help with generalization.
- Early stopping. Iterative algorithms (CNN, DNN, RNN, etc.) suffer from the local minima problem. Stopping on time can give you better results.
Hopefully, you will consider reading Funes the memorious or any Borges tale. And hopefully, you will think about Funes when you find your next overfitted model.